ebpf入门
eBPF(extended Berkeley Packet Filter),ebpf 支持程序在不修改内核源码,或添加额外内核模块情况下运行,添加内核新功能。
架构
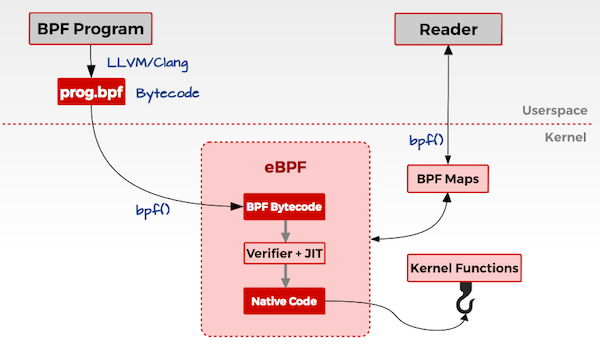
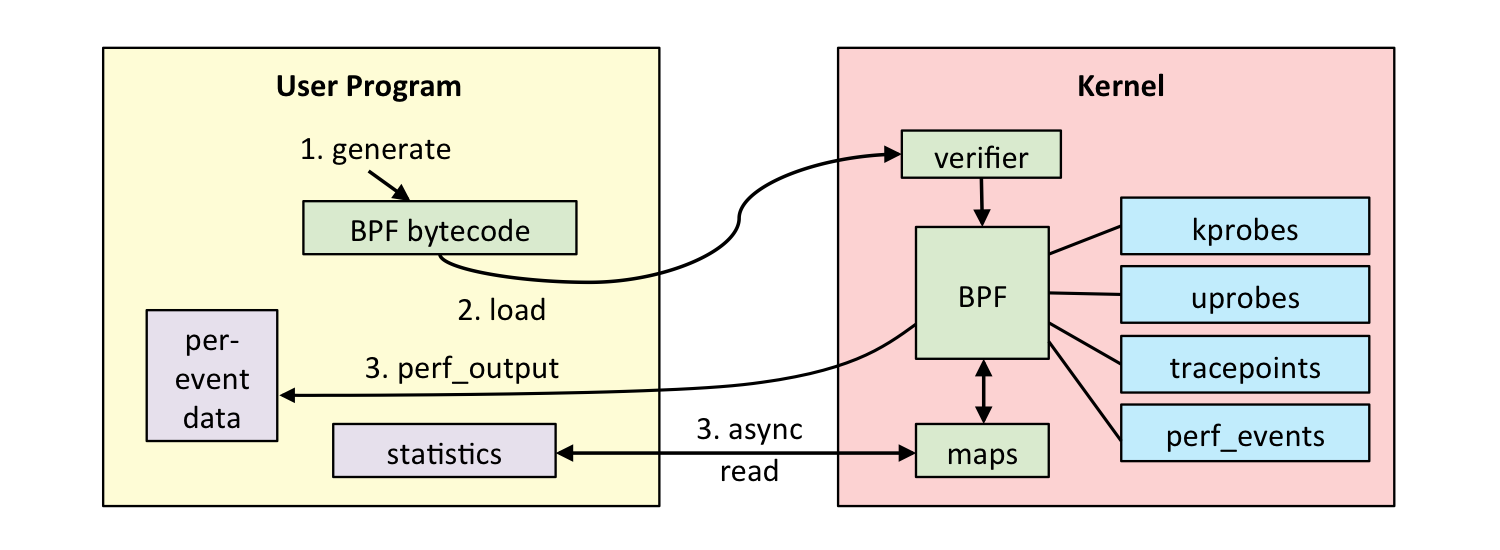
用户态
- 用户编写 ebpf 程序,可使用 ebpf 汇编或者 ebpf 特有 c 语言编写;
- 使用 llvm/clang 编译器,将 ebpf 程序编译为 ebpf 字节码;
- 调用 bpf() 系统调用将 eBPF 字节码加载到内核
内核态
- ebpf 字节码到内核时,内核会先对其进行安全验证;
- 使用 JIT (Just In Time)将 字节码编译为本地机器码;
- 根据 eBPF 程序功能,将机器码挂载到内核的不同运行路径上(例如跟踪内核运行状态的ebpf 程序会挂载在 kprobes 的运行路径上)。当内核运行到这些路径上,就会触发执行相应路径上的 eBPF 机器码;
原文拿来和 JAVA 的 AOP 概念做类比,这里由于本人没有 java 基础,所以不再赘述,感觉只是挂钩函数功能而已,欢迎评论区指正 orz…
根据挂载点功能不同,可以分为以下几个模块:
- 性能跟踪;
- 网络;
- 容器;
- 安全
eBPF 使用
编写 eBPF 程序方式有直接汇编,c语言形式,bcc 工具。
bpftrace
下面是一些简单命令用来入门了解,详细文档参考 bpftrace language
One-Liner Tutorial
Lesson 1. Listing Probes
1 | bpftrace -l 'tracepoints:syscalls:sys_enter_*' |
bpftrace -l 列举所有 probes,然后跟一个搜索字段
Lesson 2. Hello World
1 | bpftrace -e 'BEGIN { printf("hello world\n"); }' |
BEGIN特殊 probe ,在程序开始时运行,可以用来设置变量以及打印头信息;- action {} ,这里调用了 printf 函数
Lesson 3. File Opens
1 | bpftrace -e 'tracepoint:syscalls:sys_enter_openat { printf("%s %s\n", comm, str(args.filename)); }' |
Lesson 4. Syscall Counts By Process
1 | bpftrace -e 'tracepoint:raw_syscalls:sys_enter { @[comm] = count(); }' |
总结进程进行系统调用的次数
- @:表示 map 特殊变量类型,可以存储总结数据。可以使用
@name提高可读性; - []:key
- count():map 类型调用次数计数
Lesson 5. Distributino of read() Bytes
1 | bpftrace -e 'tracepoint:syscalls:sys_exit_read /pid == 18644/ { @bytes = hist(args.ret); }' |
总结 sys_read() 内核函数的返回值并以直方图格式返回
- /…/:过滤
- ret:函数返回值
- @:map 无key
- hist:map 函数
Lesson 6. Kernel Dynamic Tracing of read() Bytes
1 | bpftrace -e 'kretprobe:vfs_read { @bytes = lhist(retval, 0, 2000, 200); }' |
- probe 采用 kretprobe:vfs_read
Lesson 7. Timing read()s
1 | bpftrace -e 'kprobe:vfs_read { @start[tid] = nsecs; } kretprobe:vfs_read /@start[tid]/ { @ns[comm] = hist(nsecs - @start[tid]); delete(@start, tid); }' |
总结消耗在 read() 上的 时间。
Lesson 8. Count Process-Level Events
1 | bpftrace -e 'tracepoint:sched:sched* { @[probe] = count(); } interval:s:5 { exit(); }' |
- sched:sched 类型 probe
- probe:当前 probe 全名
- intervals:s:5:持续5s
- exit():退出bpftrace
Lesson 9. Profile On-CPU Kernel Stacks
1 | bpftrace -e 'profile:hz:99 { @[kstack] = count(); }' |
- profile:hz:99:设置cpu为99hz。需要足够的cpu时间来捕获执行,但又不能影响执行。100可能与lockstep或其他定时活动冲突,故选择99
- kstack:内核函数调用栈
Lesson10. Scheduler Tracing
1 | bpftrace -e 'tracepoint:sched:sched_switch { @[kstack] = count(); }' |
过滤了 上下文切换的 events。
Lesson 11. Block I/O Tracing
1 | bpftrace -e 'tracepoint:block:block_rq_issue { @ = hist(args.bytes); }' |
块设备 I/O 请求
- tracepoint:block:block类型的 tracepoint
- block_rq_issue:当设备存在 I/O 时触发
- args.bytes:block_rq_issue 的参数,请求的字节大小
Lesson 12. Kernel Struct Tracing
1 | cat path.bt |
跟踪了 vfs_open() 内核函数,并解析其 第一个参数 struct path *。
- kprobe
- arg0:自带变量,表示第一个参数
((struct path *)arg0)->dentry->d_name.name:将 arg0 转换为 struct path 类型。#include包含含有struct path定义的文件。
bcc
bcc 工具安装命令
1 | sudo pacman -S bcc bcc-tools python-bcc |
Lesson 1. hello world
运行以下 hello world python 程序
1 | #!/usr/bin/python |
text='...':定义了 BPF 程序。c语言;kprobe__sys_clone():基于 kprobes,如果函数定义前缀为kprobe__,剩下的则被认为是要插桩的内核函数,(上例中没有用到,因为较新内核中clone为__x64_sys_clone,而其会自动修正为sys_clone导致报错)void *ctx:ctx 保存了 参数,但是由于这里没有使用,直接转换为 void 类型;bpf_trace_printk():内核打印函数,基于trace_pipe。但本身参数存在限制,最多3个参数,只能有一个%s,并且trace_pipe全局共享。更好的调用接口是BPF_PERF_OUTPUT。return 0:必要的格式,并且 内核内部对不同返回值有不同处理逻辑,未定义会导致UB行为.trace_print:bcc 例程读取trace_pipe并打印输出
Lesson 2. sys_sync()
仿照前面 hello world 编写即可
1 | from bcc import BPF |
Lesson 3. hello_fields.py
1 | from bcc import BPF |
trace 与 hello_world 类似,但加了一些新东西:
prog =:定义 c 程序为 prog 变量hello():使用自定义函数名,而非kprobe__。BPF c 程序中的所有 c 函数会在 probe 中执行,因此他们会将pt_reg* ctx作为第一个参数。如果不需要执行,需要定义为static inline,有时候需要__always_inline属性。b.attach_kprobe(event="__x64_sys_clone", fn_name="hello"):创建一个 kprobe。可以多次 attach_kprobe,也可以将一个 c 函数 attach 到多个内核函数中。b.trace_fields:返回 trace_pipe 中的固定字段集合。类似于 trace_print()。
Lesson 4. sync_timing.py
过去 sync 实现是异步的,导致 系统管理员会连敲三个
sync命令等待完成,再 reboot,有人sync; sync; sync这个不会等待直接执行,自然起不到等待sync的作用。现在 sync 是同步实现,会阻塞(不过运行很快)。
sync_timing.py 实现了 trace sync 并检测命令间隔运行是否超过 1s。
1 | from __future__ import print_function |
bpf_ktime_get_ns():返回当前纳秒级时间戳BPF_HASH(last):创建一个 BPF map 对象 (hash表)。默认 key value 类型为 u64。key=0:这里只使用了 key = 0 的情况。last.lookup(&key):在 hash 表中查询 key,如果存在返回指向该值的指针。否则为空。参数为 key 的指针地址if (tsp != NULL) {:bpf 的 verifier 要求从 lookup 获取的指针变量必须检查是否为空。以防空指针引用last.delete(&key):删除 key。这里先删除再update是由于 4.8.10 内核版本 update 函数存在 bug,新版本注释改行无影响last.update(&key, &ts):修改 key 对应的 value。
Lesson 5. sync_count.py
修改 sync_timing.py,令其能够保存所有的 kernel sync 系统调用,以 hash map 结构存储
1 | from __future__ import print_function |
Lesson 6. disksnoop.py
1 | #!/usr/bin/python3 |
REQ_WRTIE:python中定义内核常量,用于后续比较;trace_start(struct pt_regs *ctx, struct request *req):参数ctx用于寄存器以及 BPF 上下文,实际参数req,req为 attach 函数blk_start_request的实际参数。start.update(&req, &ts):以 struct 结构体作为 key,常见的可以作为 key 的还有 thread id。req->_data_len:可以解引用struct request的成员。bcc 是通过封装bpf_probe_read_kernel函数来实现的,也可以自行调用来实现。if BPF.get_kprobe_functions(b'__blk_account_io_done'):...:根据 kernel 版本来选择不同 attach 的函数。
Lesson 7. hello_perf_output.py
使用 BPF_PERF_OUTPUT() 接口而不是 bpf_trace_printk。hello_perf_output.py
1 | from bcc import BPF |
struct data_t:定义了要返回给用户空间的结构体;BPF_PERF_OUTPUT:命名了通信信道events;struct data_t data = {};:初始化;bpf_get_current_pid_tgid():返回进程id(低四字节)以及线程组id(高四字节)bpf_get_current_comm():返回进程命令events.perf_submit:通过 perf ring buffer 提交 event 到用户空间def print_event():定义可以处理 event 流的函数b["events"].event(data):获取 perf 返回 event作为一个 python 对象。b["events"].open_perf_buffer(print_event):将events 与 print_event 函数联系while1: b.perf_buffer_poll(),阻塞等待 events
Lesson 8. sync_perf_output.py
重写 sync_timing.py
1 | from __future__ import print_function |
Lesson 9. bitehist.py
直方图输出工具
1 | #!/usr/bin/python3 |
Lesson 10. disklatency.py
根据 disksnoop.py 以及 bitehist.py 编写程序,此处略
Lesson 11. vfsreadlat.py
分离 python 以及 c,通过 BPF(src_file="")实现
Lesson 12. setuid_monitor.py
1 | from __future__ import print_function |
TRACEPOINT_PROBE(syscalls, sys_enter_setuid)tracepoint 提供了稳定的 api,(例如 sys_enter_setuid),因此可以尽量使用 tracepoint 而非 kprobe。通过perf list查找可用 tracepointsargs->uid:args 为 tracepoint 提供的。定义文件位置如下,setuid 情况只有 uid 一个成员会被打印1
2
3
4
5
6
7
8
9
10
11❯ sudo cat /sys/kernel/tracing/events/syscalls/sys_enter_setuid/format�
name: sys_enter_setuid�
ID: 204�
format:
� field:unsigned short common_type; offset:0; size:2; signed:0;
� field:unsigned char common_flags; offset:2; size:1; signed:0;
� field:unsigned char common_preempt_count; offset:3; size:1; signed:0;
� field:int common_pid; offset:4; size:4; signed:1;
�� field:int __syscall_nr; offset:8; size:4; signed:1;
� field:uid_t uid; offset:16; size:8; signed:0;
print fmt: "uid: 0x%08lx", ((unsigned long)(REC->uid))- BPF_PERF_OUTPUT perf_submit 第一个参数为
args
Lesson 13. disksnoop.py fixed
…
Lesson 14. strlen_count.py
对用户空间的函数进行插桩,strlen()。
1 | from __future__ import print_function |
PT_REGS_PARM1(ctx):获取strlen()的第一个参数b.attach_uprobe(name="c", sym="strlen", fn_name="count"):挂载到库”c”,如果挂载 main 主程序,填入其 “pathname”。
Lesson 15. nodejs_http_server.py(USDT)
usdt(user statically-defined tracing)
##0## Lesson 16. task_switch.c
暂略
C程序编写
首先有一个最小的 bpf 库:
1 | /* eBPF instruction mini library */ |
另外还有一些 main.c 中可用的模板函数:
1 |
|
BPF中的寄存器为 BPF_REG_R0-10 其中 R0 为结果寄存器,R1-R3 为参数寄存器,R10 为栈帧寄存器。
BPF Verifier
Verifier 为抽象解释器,不关注变量实际取值,而是将目标作为一个变量范围表示。因此其 ebpf 代码存在很多限制,例如 算术右移操作的右值必须为常数 src_is_const,如果为变量,则其右移后的值会变得无法预测。
如下,在 verifier 中,实际会使用 umin_value 来右移,这里如果我们设置右值变量 [0, 1], dst_reg 为常数 1,则会导致 dst_regs 在 verifier 中变为 1,而在真实执行中如果我们设置了右值变量为1,就会导致 dst_regs 值为0,从而可以导致后面更大的混淆以及利用。

一般就是出现混淆后,构造 verifier 认为为0,但实际上非0的情况,然后可以将其作为偏移写入目标 BPF_MAP 对象的 max_entries 以及 index_mask 字段,从而可以对 MAP 对象的任意 index 做读写