LibAFL论文笔记
论文概述
本文提出一个新的工具LibAFL,旨在将AFL工具模块化,方便后续各项工作以及改进的集成。
看论文似乎AFL++也提供了高度配置化的模糊测试框架,但是不够通用
拟解决问题
- 正交性质的工作难以整合集成;
- 论文个体贡献难以评估:因为无法判断是基于的工具的优势还是创新算法的优势
- 难以比较不同工作;
论文贡献
提出LibAFL,基于Rust实现的模糊测试框架。LibAFL包含了一系列的库可以用于定制化fuzzer。
几个特性:
- 易于扩展;
- 按现在的fuzzer组成部分划分
- Rust编写
- 实现了大量的模糊测试算法,特性以及插桩选项
背景
关于fuzzing的定义:
Therefore, we believe it is more appropriate today to think of fuzzing as a family of testing techniques, which repeatedly provide machine-generated inputs to a target system with the aim of finding inputs that satisfy certain objectives.
注:灰盒的运行效率可能要优于白盒,因为不会像白盒插桩粒度那么细致
AFL++
吸取了多种针对AFL的改进技术,其作者重新实现了一些改进例如MOpt,AFLFast;并且提供了插件接口(custom mutators),可以自定义变异策略以及测试case minimization。
但是没有进行模块化开发
Fuzz 组成部分
分为9个组成部分
- Input:几种表现形式,bytearray、AST、token、IR
- Corpus:存放硬盘,两种语料库(存放interesting testcases,crash)
- Scheduler:获取下一个用于fuzz的testcase的方式。例如FIFO或者随机选择…有的工作会做这方面工作,贡献是解决插桩粒度太细致导致语料库爆炸的问题
- Stage:定义对testcase执行的操作。Scheduler选择一个case然后fuzzer每stage执行输入。通常为调用mutator或者analysis stage进行污点分析,或者指minimize corpus size
- Observer:从一次执行中获取目标执行信息。eg:coverage map。
- Executor:执行目标的方式。
- Feedback:将执行结果是否interesting进行分类。例如决定是否输入被加入语料库,以及是否crash
- Mutator:对输入进行变异
- Generator:生成新Input的部分
架构
核心架构如下:
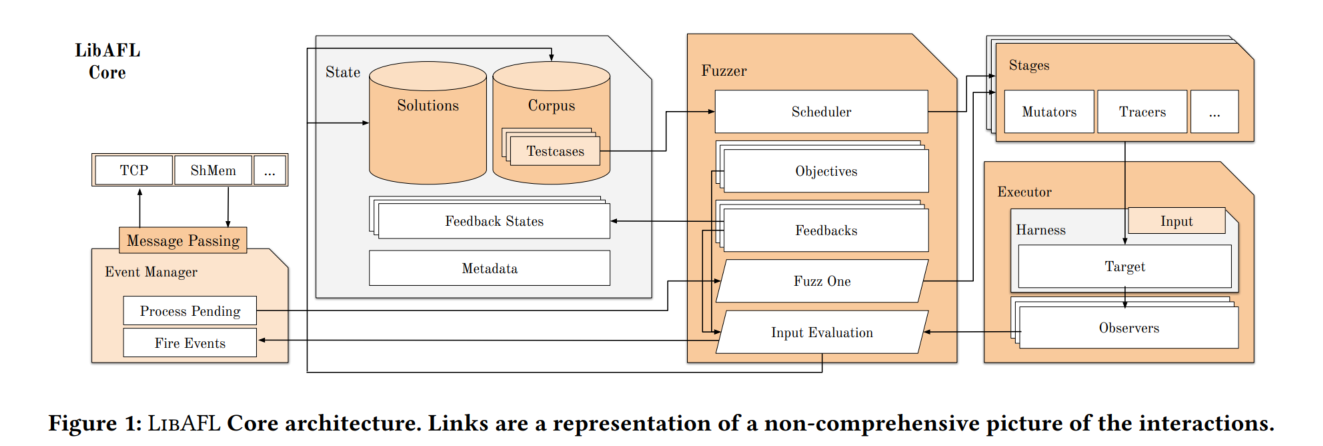 三个核心库:
三个核心库:
- LibAFL Core:主要库,包含模糊测试组成部分以及实现。
- LibAFL Targets:包含要与目标程序依存交互的代码,例如coverage tracking
- LibAFL CC:提供编译的wrapper
Instrumentation Backends:提供了后端执行引擎的API
Fuzzer Frontends:所有用于创建fuzzer的库都是前端
应用与实验
集中于四个方面:roadblocks bypassing, structure-aware fuzzing, corpus scheduling, energy assignment
通过三种实验集合来评估:
- 代码覆盖率以及漏洞检测的效果
- 集成在LibAFL框架的能力
- 与AFL++ HonggFuzz进行比较
Bypassing Roadblocks
通过绕过或者通过复杂的约束条件来提升代码覆盖率。
LibAFL提供了多种方法来进行绕过:
- value-profile:由LibFuzzer提出,通过最大化指令中两个操作数的匹配比特位数。
- cmplog:由RedQueen、Weizz使用,通过插桩比较指令以及以指针变量作为参数的函数,并记录运行时相关的值。
- autotokens:由AFL++提出,基于LTO pass插桩可以使用,提取比较指令中的tokens以及包含立即数的函数。由于不会引入运行时开销,因此可以作为基线
结果:cmplog效果最优,其次是value_profile_cmplog,然后是plain,即baseline,最后是value_profile。原因可能是autotokens方法已经足够优秀,并且value_profile会引入更多的插桩信息,导致可能并不会带来很好的绕过效果。
Structure-aware Fuzzing
令fuzzer基于输入格式进行模糊测试。
- Nautilus是一个基于语法的覆盖率导向的fuzzer,通过树结构对语料进行建模。变异策略则是子树生成以及替换。
- Gramatron:基于语法的fuzzer。
- 语法学习:Grimoire,基于输入生成树状输入,并进行语法的变异,针对JavaScript的
Corpus Scheduling
- FIFO/Random
- AFL的权重计算公式
- AFL++的基于概率统计的采样方法
- TortoiseFuzz的基于三种安全影响度量方式,内存操作,函数粒度,循环
结果:AFL++的结果最好,AFL次之,TortoiseFuzz,然后随机的基线策略其实效果也很不错
Energy Assignment
该部分负责一个输入需要被变异多少次来生成新的testcases
- 固定值,或者随机值
- AFLFast提供了6种算法:exploit(基于执行时间、覆盖率等标准给予power),explore(降低exploit给定的power),coe(指定0,直到触发边变为低频),fast(基于高频边来指定),lin(基于时间线性变化),quad(二次函数变化)
结果:explore > fast > plain > coe
A Generic Bit-level Fuzzer
与其他工具(LibFuzzer, AFL++, HonggFuzz)的比较
结果:LibAFL > HonggFuzz > AFL++ > Entropic(LibFuzzer)
Differential Fuzzing
似乎是对以太坊的,先暂时不涉及
讨论
仍然缺少一些对象的实现部分,eg: directed fuzzing approaches
集成了静态分析API,SYMCC,SYMQEMU