Fudge: Fuzz Driver Generation at Scale
摘要
google针对c与c++库提出了新的fuzz driver自动化生成方式。
解决问题
对C/C++库代码片段的slice_based_fuzz。
主要贡献
基于google海量代码库进行测试,完成了Fudge可以有效的处理海量的代码。发现其中的安全漏洞
尚存不足
fuzz基于源代码,可以考虑在编译源代码为可执行文件后加入动态符号执行等技术。(也在其Future Work中体现(还提到了Machine Learning))
Fudge具体过程
Slicing Phrase
从google代码库中选出有关库函数的代码,以FreeImage库为例,slicer模块会扫描整个代码库,运行每一个源文件,假设slicer处理如下代码:
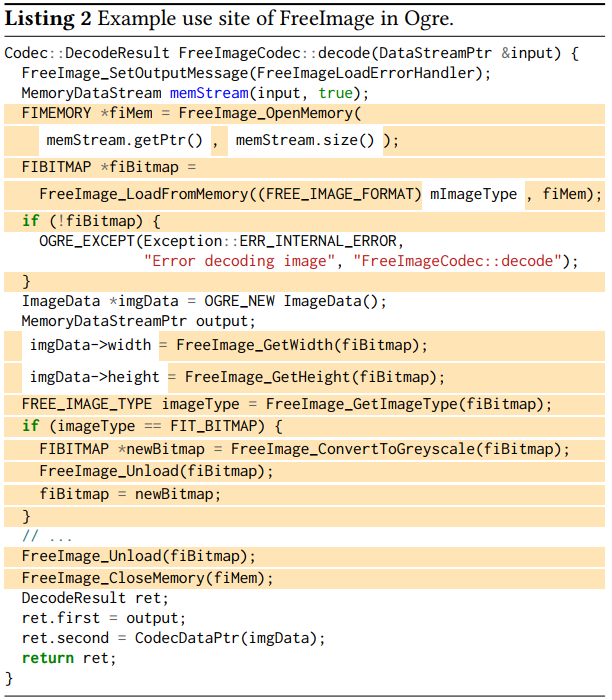
slicer会分析函数的抽象语法树(AST),假如函数中存在对目标库函数(需要有解析api接口,即输入)的调用,slicer首先选择所有FreeImage调用语句,然后根据控制流和数据流依赖关系来扩充语句。当其中符号不是在函数内部定义或类型不是目标库函数定义时,不挑选该符号,置为UnknownX(如上图imgData->width非库函数定义类型,mImageType也非库函数内部定义类型)
控制流与数据流依赖关系参考:[https://blog.csdn.net/hmysn/article/details/124717162]
提取出的代码如下,slicer会重新建立新的ast以供下一阶段使用:

Synthesis phase
Synthesis模块接收提取的代码片段并填充其成为可供fuzzer fuzzing的函数。
对于一个UnknownX有多种重写方式,以上图中mImageType为例,既可以作为fuzzer的fuzzing对象,又可以直接设置为默认值0或1等常量。

重写UnknownX的算法如下,将slicer提取到的代码段的ast列表作为输入,pop列表中ast,对其做完整性检查,若不完整,则对其中UnknownX进行重写,并将重写后的ast重新加入incomplete_asts列表(需要保证重写后ast不重复,增加了seen_before的检验),若完整则将ast加入到complete_asts列表中,一直循环直到incomplete_asts列表变为空值。

Evaluation phrase
评估fuzz driver是否合适的两个标准 1)是否fuzz了正确的api(人工检验),2)api是否正确调用(自动检验,通过比较target的崩溃时间)
另外还有评价好坏的标准:
- The candidate should build successfully.
- It should run successfully without generating a crashing input for at least a few seconds.
- The size of the minimized corpus of the target should be larger than some lower threshold.
- The larger the number of lines of the library covered, the better. We measure both absolute coverage and increase in coverage relative to the existing fuzz drivers for the library.
User Interface
提供了用户界面的ui。